In the heap data structure, the root node is compared with its children and arranged according to the order. So if a is a root node and b is its child, then the property, key (a)>= key (b) will generate a max heap.
The above relation between the root and the child node is called as “Heap Property”.
Depending on the order of parent-child nodes, the heap is generally of two types:
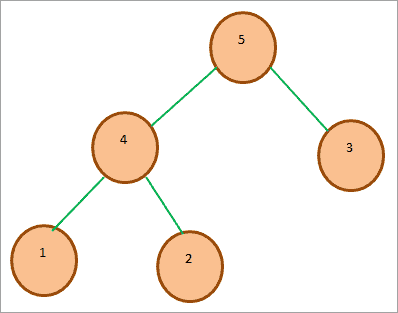
#1) Max-Heap: In a Max-Heap the root node key is the greatest of all the keys in the heap. It should be ensured that the same property is true for all the subtrees in the heap recursively.
The below diagram shows a Sample Max Heap. Note that the root node is greater than its children.
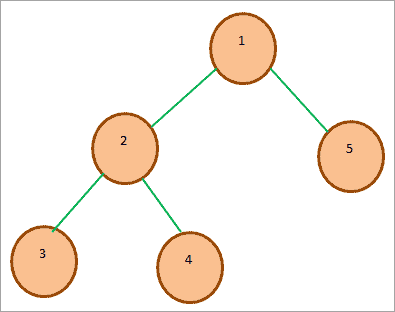
#2) Min-Heap: In the case of a Min-Heap, the root node key is the smallest or minimum among all the other keys present in the heap. As in the Max heap, this property should be recursively true in all the other subtrees in the heap.
An example, of a Min-heap tree, is shown below. As we can see, the root key is the smallest of all the other keys in the heap.
A heap data structure can be used in the following areas:
- Heaps are mostly used to implement Priority Queues.
- Especially min-heap can be used to determine the shortest paths between the vertices in a Graph.
As already mentioned, the heap data structure is a complete binary tree that satisfies the heap property for the root and the children. This heap is also called a binary heap.
Binary Heap
A binary heap fulfills the below properties:
- A binary heap is a complete binary tree. In a complete binary tree, all the levels except the last level are completely filled. At the last level, the keys are as far as left as possible.
- It satisfies the heap property. The binary heap can be max or min-heap depending on the heap property it satisfies.
A binary heap is normally represented as an Array. As it is a complete binary tree, it can easily be represented as an array. Thus in an array representation of a binary heap, the root element will be A[0] where A is the array used to represent the binary heap.
So in general for any ith node in the binary heap array representation, A[i], we can represent the indices of other nodes as shown below.
| A [(i-1)/2] | Represents the parent node |
|---|---|
| A[(2*i)+1] | Represents the left child node |
| A[(2*i)+2] | Represents the right child node |
Consider the following binary heap:
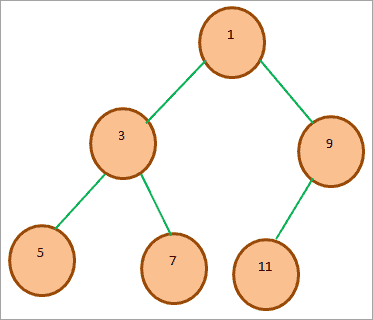
The array representation of the above min binary heap is as follows:
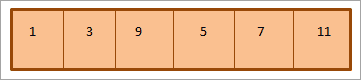
As shown above, the heap is traversed as per the level order i.e. the elements are traversed from left to right at each level. When the elements at one level are exhausted, we move on to the next level.
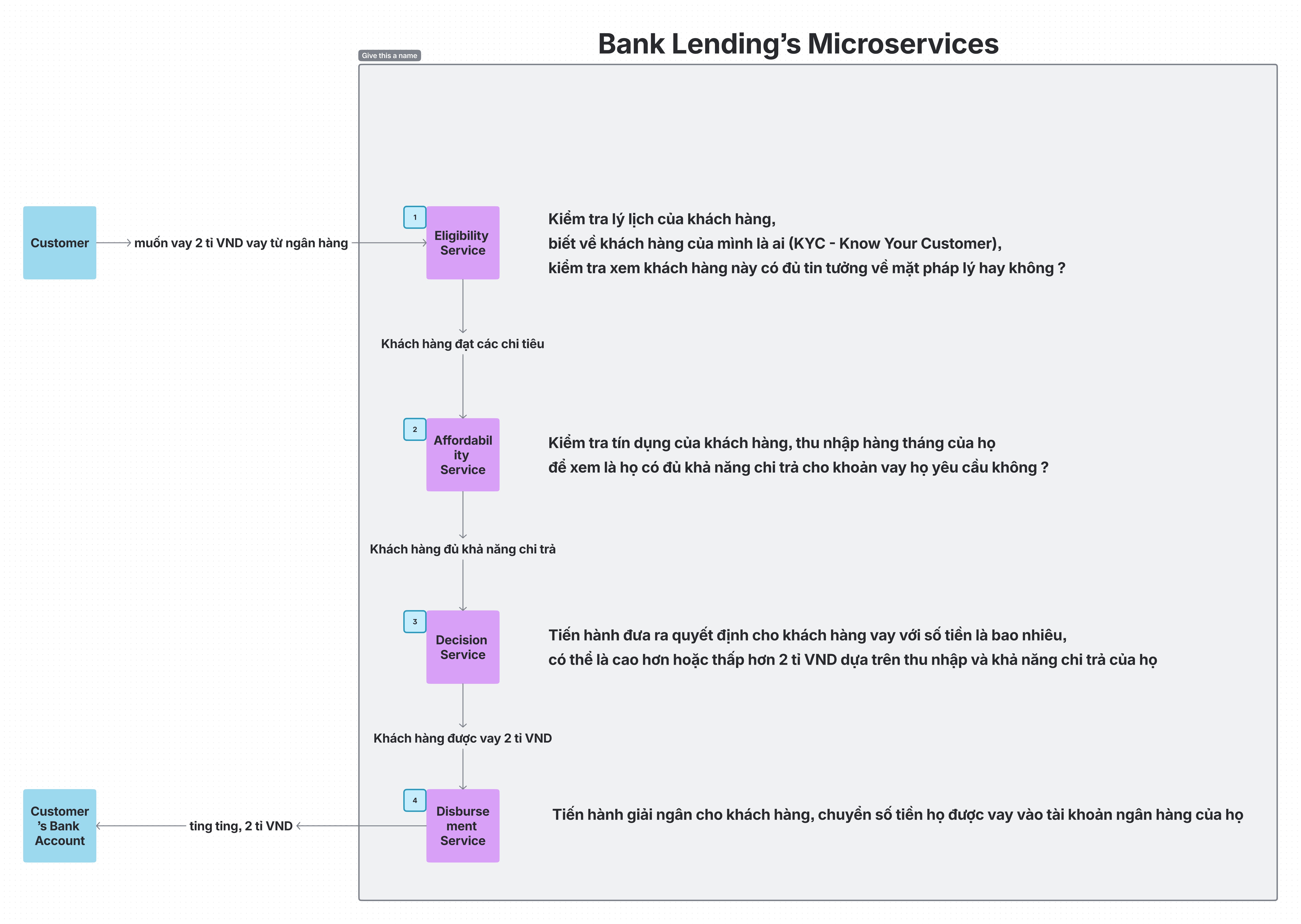
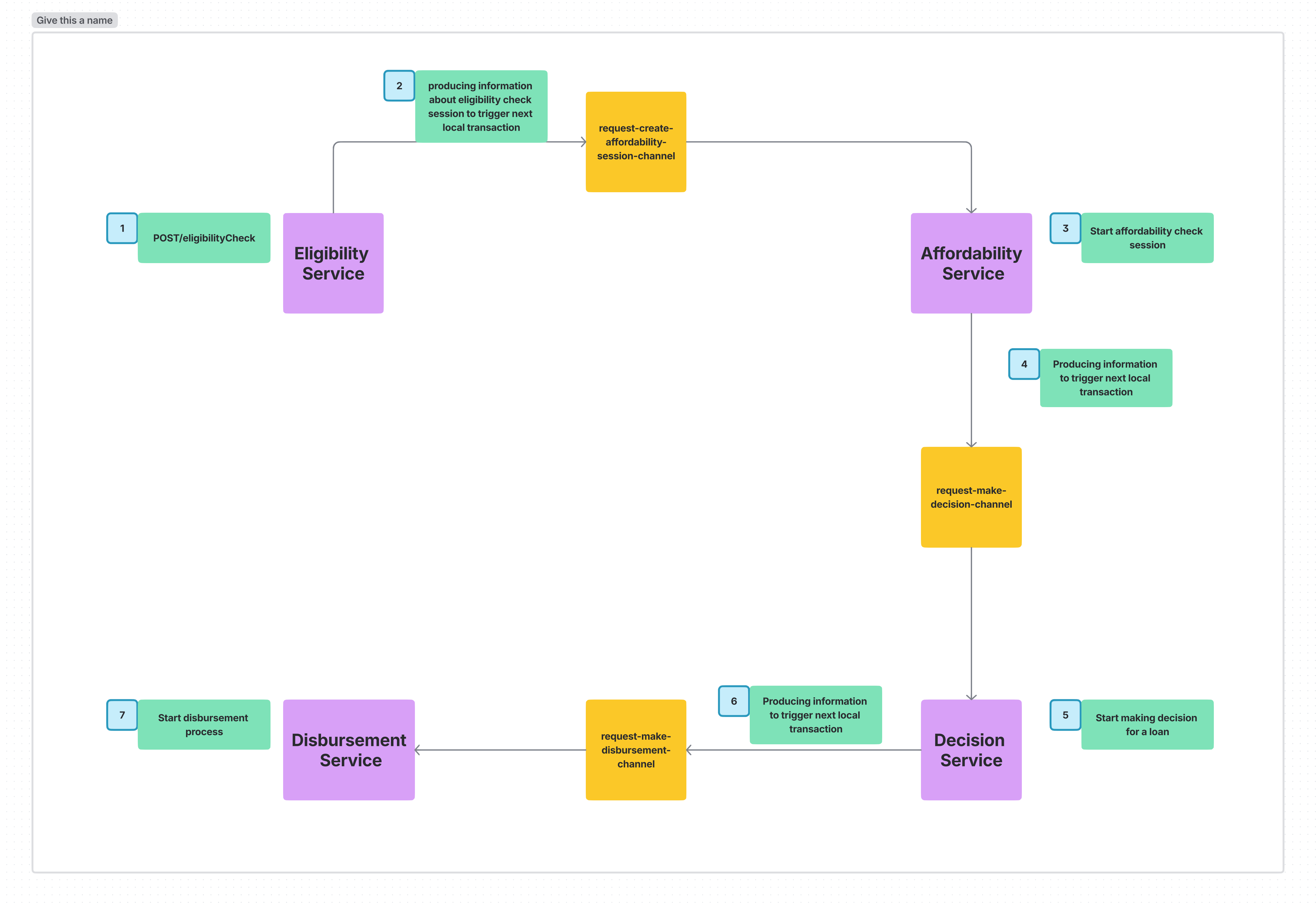
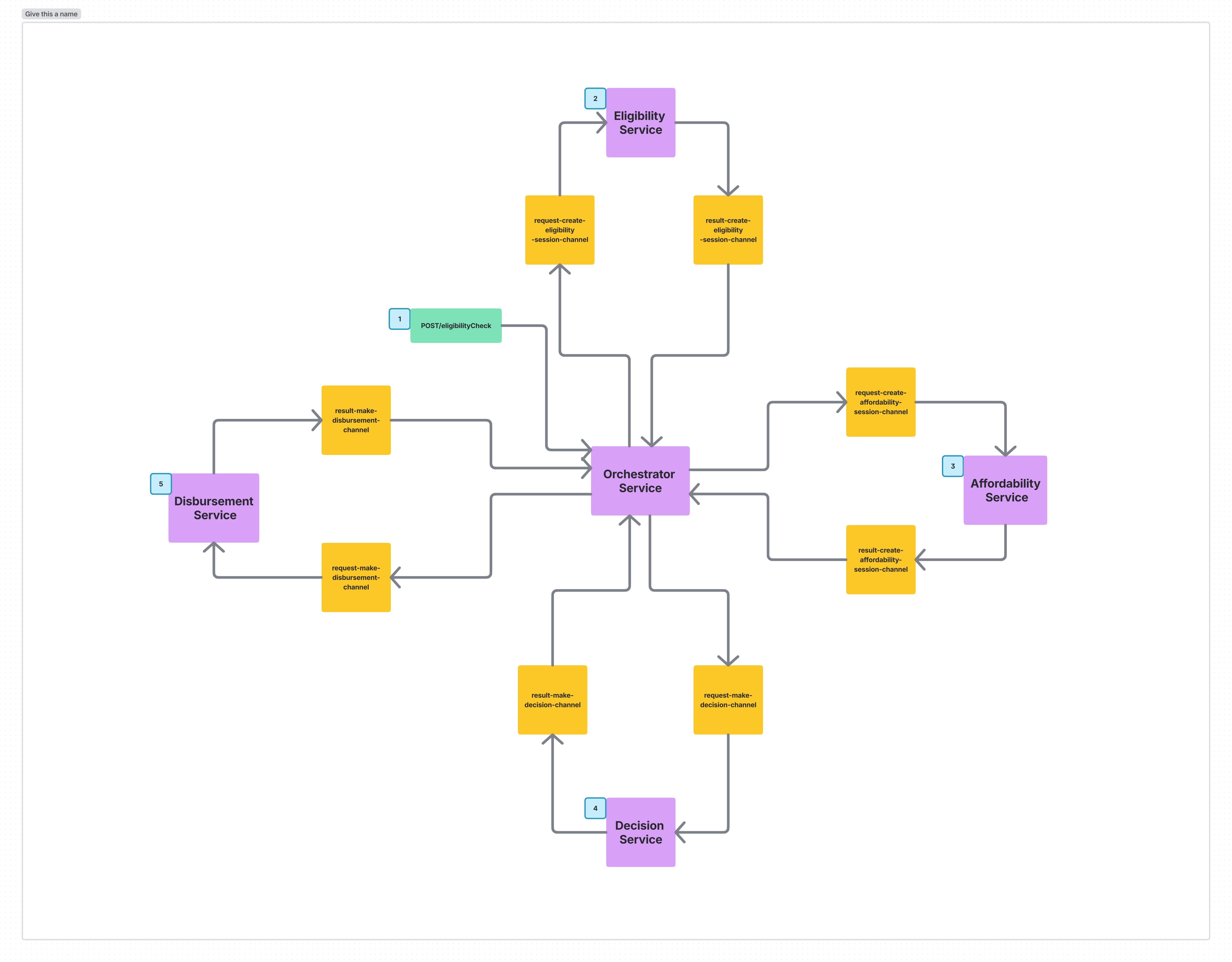
- The
Customer Serviceattempts to reserve credit - It then sends back a reply message indicating the outcome
- The saga orchestrator either approves or rejects the
Order